Explicació del notebook Colab: TinyML amb IoT-02
Aquest document explica pas a pas el codi del notebook TinyML_IoT02_pipeline.ipynb,
que implementa el pipeline complet per entrenar un model de classificació ambiental
i desplegar-lo en un microcontrolador ESP32.
L'objectiu final és que un ESP32 de 3€ pugui classificar l'entorn en quatre estats
(NORMAL, CALOR, FOSCOR, MOLT LLUMINÓS) a partir de tres sensors —temperatura,
humitat i lluminositat— sense cap connexió al núvol i en menys d'un mil·lisegon.
Pas 1 — Imports i verificació de versions
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import os
print(f"TensorFlow: {tf.__version__}")
print(f"NumPy: {np.__version__}")
print("✓ Tot llest")
Sortida real:
TensorFlow: 2.20.0
NumPy: 2.0.2
✓ Tot llest
Les tres biblioteques principals que s'utilitzen al llarg del notebook són:
- NumPy (
np): per generar i manipular les dades numèriques (arrays, operacions matemàtiques). - TensorFlow / Keras (
tf): per definir, entrenar i convertir el model de xarxa neuronal. - Matplotlib (
plt): per visualitzar les dades i les corbes d'entrenament.
TensorFlow ja ve preinstal·lat a Google Colab, de manera que no cal instal·lar res manualment.
Pas 2 — Definició de zones i generació de dades
Per què dades sintètiques?
En un projecte real, les dades d'entrenament provindrien de sensors físics en condicions
reals de funcionament. En aquest cas, com que treballem amb un simulador, generem dades
sintètiques que reprodueixen el comportament esperat del hardware.
⚠️ La lliçó del model v1
La primera versió d'aquest model va ser entrenada amb zones sintètiques mal ajustades.
El simulador IoT-02, quan ningú toca els controls, retorna LDR = 500. Normalitzat:
500 ÷ 4095 = 0.12. La zona FOSCOR del model v1 anava de 0.00 a 0.15. Resultat:
el model classificava l'estat normal com a FOSCOR malgrat tenir un 99.7% d'accuracy
(exactitudoprecisió) en el test sintètic.Accuracy (
exactitudoprecisió) alta no significa model útil. Un model és tan bo com les dades
amb les que ha après. Aquesta versió (v2) corregeix les zones a partir dels
valors reals mesurats al simulador.
Fixar les llavors (reproduïbilitat)
np.random.seed(42)
tf.random.set_seed(42)
Aquestes dues línies asseguren que els nombres aleatoris generats siguin sempre
els mateixos cada vegada que s'executa el codi. És una pràctica estàndard en ML:
permet replicar exactament els mateixos resultats i comparar experiments de forma justa.
Normalització de les entrades
Abans de generar cap dada, cal entendre com es normalitzen els tres sensors.
Les xarxes neuronals aprenen millor quan totes les entrades estan en el mateix ventall (range) [0, 1]:
| Sensor | Valor real | Normalització | Ventall normalitzat |
|---|---|---|---|
| Temperatura | 0–50 °C | temp / 50.0 |
0.0–1.0 |
| Humitat relativa | 0–100 % | hum / 100.0 |
0.0–1.0 |
| Lluminositat LDR | 0–4095 (ADC 12 bits) | ldr / 4095.0 |
0.0–1.0 |
Aquesta normalització ha de ser idèntica entre l'entrenament (Python) i l'execució
al microcontrolador (Arduino). Si difereixen, el model farà prediccions incorrectes
sense donar cap error.
La funció generadora
N = 300 # mostres per classe
def generar_classe(n, rang_t, rang_h, rang_l, soroll=0.02):
T = np.random.uniform(*rang_t, n) + np.random.normal(0, soroll, n)
H = np.random.uniform(*rang_h, n) + np.random.normal(0, soroll, n)
L = np.random.uniform(*rang_l, n) + np.random.normal(0, soroll, n)
return np.clip(np.column_stack([T, H, L]), 0, 1).astype(np.float32)
Es crearan 300 mostres per a cadascuna de les 4 classes (1.200 mostres en total).
La funció generar_classe fa el següent per a cada sensor:
np.random.uniform: genera valors aleatoris distribuïts uniformement
dins del rang especificat. Simula la variabilitat natural de les lectures.np.random.normal: hi afegeix un petit soroll gaussià (per defecte, desviació
estàndard de 0.02). Fa les dades més realistes: cap sensor real retorna valors
perfectament uniformes.np.column_stack: agrupa els tres sensors en una matriu de columnes (T, H, L).np.clip(..., 0, 1): assegura que cap valor surti dels límits [0, 1]
malgrat el soroll afegit.
Les quatre classes (perfils ambientals)
Les zones s'han definit a partir dels valors reals mesurats al simulador IoT-02:
# Classe 0 · NORMAL
X0 = generar_classe(N,
rang_t=(18/50, 28/50), # 18–28 °C
rang_h=(0.30, 0.65), # 30–65 % RH
rang_l=(400/4095, 800/4095)) # LDR 400–800
# Classe 1 · CALOR
X1 = generar_classe(N,
rang_t=(30/50, 45/50), # 30–45 °C
rang_h=(0.65, 1.00), # 65–100 % RH
rang_l=(200/4095, 800/4095)) # LDR 200–800
# Classe 2 · FOSCOR
X2 = generar_classe(N,
rang_t=(15/50, 30/50), # 15–30 °C
rang_h=(0.20, 0.70), # 20–70 % RH
rang_l=(0/4095, 100/4095)) # LDR 0–100
# Classe 3 · MOLT LLUMINÓS
X3 = generar_classe(N,
rang_t=(15/50, 30/50), # 15–30 °C
rang_h=(0.20, 0.70), # 20–70 % RH
rang_l=(2000/4095, 4095/4095))# LDR 2000–4095
Nota que les classes NORMAL i CALOR comparteixen ventall de LDR (200–800):
el que les diferencia principalment és la temperatura i la humitat, no la llum.
Això és intencionat i reflecteix la realitat: una sala càlida no ha de ser necessàriament
fosca ni il·luminada.
Combinació, barreja i divisió
X = np.vstack([X0, X1, X2, X3])
y = np.array([0]*N + [1]*N + [2]*N + [3]*N)
idx = np.random.permutation(len(X))
X, y = X[idx], y[idx]
y_oh = tf.keras.utils.to_categorical(y, 4)
split = int(0.8 * len(X))
X_tr, X_te = X[:split], X[split:]
y_tr, y_te = y_oh[:split], y_oh[split:]
np.vstack: enganxa verticalment les quatre matrius.Xresultant té forma(1200, 3):
1.200 mostres, cadascuna amb 3 valors (T, H, L).y: vector d'etiquetes amb les respostes correctes. Els primers 300 elements
valen 0 (NORMAL), els 300 següents valen 1 (CALOR), etc.- Barreja (
permutation): és vital barrejar les dades abans d'entrenar.
Si no es barregen, el model veu primer 300 mostres de NORMAL, després 300 de CALOR, etc.,
i l'entrenament es fa inestable. Amb la barreja, cada lot (batch) d'entrenament
conté mostres de totes les classes. - One-Hot Encoding (
to_categorical): transforma les etiquetes numèriques en
vectors binaris. L'etiqueta2(FOSCOR) es converteix en[0, 0, 1, 0].
Això és necessari perquè la capa de sortida del model genera quatre probabilitats,
una per classe, i cal comparar-les amb un vector de la mateixa forma. - Divisió 80/20: el 80% de les dades (960 mostres) s'usen per entrenar.
El 20% restant (240 mostres) es reserven per al test: el model mai les veurà
durant l'entrenament, cosa que permet mesurar com generalitza a dades noves.
Sortida real:
Total mostres: 1200
Entrenament: 960
Test: 240
Distribució (test): [57 68 72 43]
La distribució [57, 68, 72, 43] indica quantes mostres de cada classe han anat
a parar al conjunt de test. Gràcies a la barreja aleatòria, és força equilibrat
(hauria d'estar proper a 60 per classe, i ho és).
Pas 3 — Visualització de les dades
Abans d'entrenar qualsevol model, convé visualitzar les dades per comprovar que
les zones estan ben definides i que el problema és resoluble.
fig = plt.figure(figsize=(12, 5))
# Vista 3D + Vista 2D (Temp vs LDR)
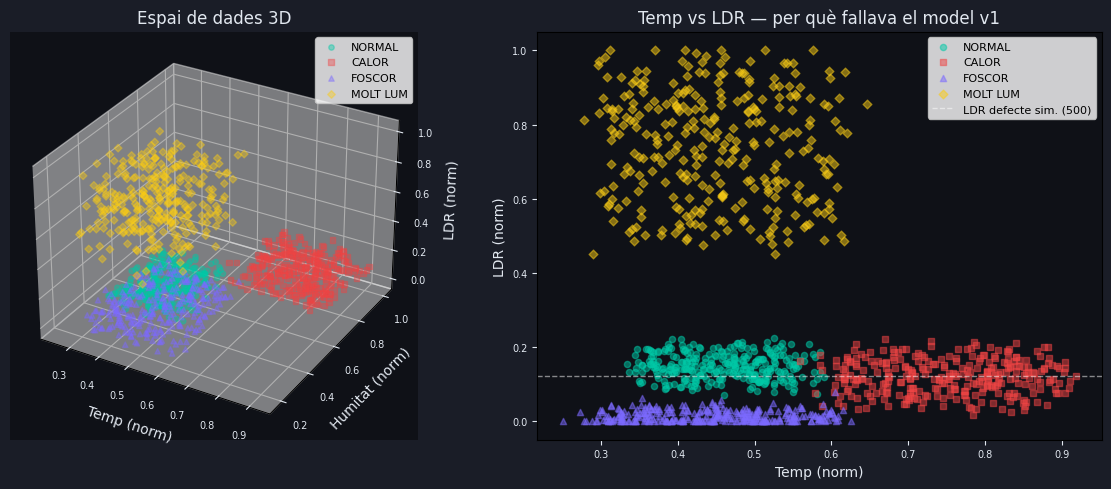
El gràfic té dues parts:
Vista 3D (esquerra): mostra les 1.200 mostres en l'espai tridimensional
(temperatura, humitat, LDR). Les quatre classes ocupen zones clarament separades,
cosa que indica que el problema és resoluble amb una xarxa neuronal relativament petita.
Vista 2D — Temp vs LDR (dreta): és la projecció més informativa per entendre
el problema. S'hi pot veure:
- NORMAL (cercles verds): temperatura 0.35–0.55, LDR 0.10–0.20.
- CALOR (quadrats vermells): temperatura 0.60–0.90, LDR 0.05–0.20.
- FOSCOR (triangles violetes): temperatura 0.30–0.60, LDR ~0.00.
- MOLT LLUMINÓS (rombos grocs): tot el rang de temperatura, LDR 0.49–1.00.
La línia discontínua marca LDR = 500/4095 = 0.122, el valor per defecte
del simulador quan ningú toca els controls. En el model v1, la zona FOSCOR
arribava fins a LDR = 0.15 (614 en valor ADC). Com que 0.122 < 0.15,
el simulador en repòs queia dins la zona FOSCOR i el model ho classificava incorrectament.
En el model v2, la zona FOSCOR s'ha redefinit fins a LDR = 100/4095 = 0.024,
molt per sota del valor per defecte. El problema queda resolt.
Pas 4 — Definició i entrenament del model
Arquitectura
model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(3,)),
tf.keras.layers.Dense(12, activation='relu'),
tf.keras.layers.Dense(8, activation='relu'),
tf.keras.layers.Dense(4, activation='softmax')
], name='classificador_ambient_v2')
El model és una xarxa neuronal feedforward (cap endavant) amb tres capes denses:
Entrada (3 valors: T, H, L)
↓
Dense(12, ReLU) ← 48 paràmetres
↓
Dense(8, ReLU) ← 104 paràmetres
↓
Dense(4, Softmax) ← 36 paràmetres
↓
Sortida (4 probabilitats: NORMAL, CALOR, FOSCOR, MOLT_LLUM)

Per què ReLU? La funció d'activació ReLU (Rectified Linear Unit) introdueix
no-linealitat: retorna el valor si és positiu, i zero si és negatiu. Sense activacions
no lineals, totes les capes denses equivaldrien a una sola capa lineal i el model
no podria aprendre fronteres complexes entre les classes.
Per què Softmax? La capa de sortida usa Softmax, que transforma quatre valors
arbitraris en quatre probabilitats que sumen exactament 1.0. Si l'entrada és clarament
CALOR, la sortida podria ser [0.0, 1.0, 0.0, 0.0]. En zones de frontera,
podria ser [0.1, 0.7, 0.2, 0.0], cosa que dóna informació sobre la incertesa
del model (útil en producció).
Sortida real del model.summary():
Model: "classificador_ambient_v2"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
│ dense (Dense) │ (None, 12) │ 48 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_1 (Dense) │ (None, 8) │ 104 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_2 (Dense) │ (None, 4) │ 36 │
└─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 188 (752.00 B)
Trainable params: 188 (752.00 B)
Non-trainable params: 0 (0.00 B)
Total paràmetres: 188
Mida estimada en memòria: ~0.7 KB (float32)
D'on surten els 188 paràmetres? Cada capa densa connecta totes les neurones
d'entrada amb totes les de sortida, més un biaix per neurona:
| Capa | Càlcul | Paràmetres |
|---|---|---|
| Dense(12) | 3 entrades × 12 + 12 biaixos | 48 |
| Dense(8) | 12 entrades × 8 + 8 biaixos | 104 |
| Dense(4) | 8 entrades × 4 + 4 biaixos | 36 |
| Total | 188 |
Per comparar: GPT-4 té aproximadament 1.800.000.000.000 paràmetres.
El nostre model és 9.570.000.000 vegades més petit i fa exactament la feina
que necessita, sense malbaratament.
Compilació i entrenament
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.005),
loss='categorical_crossentropy',
metrics=['accuracy']
)
history = model.fit(
X_tr, y_tr,
epochs=150,
batch_size=32,
validation_split=0.15,
verbose=0
)
Adam(Adaptive Moment Estimation): l'optimitzador que ajusta els 188 paràmetres
del model en cada pas d'entrenament per reduir l'error. És l'optimitzador estàndard
per a la majoria de xarxes neuronals petites i mitjanes.categorical_crossentropy: la funció de pèrdua (loss) per a problemes
de classificació multiclasse. Mesura com de lluny estan les probabilitats predites
de les etiquetes reals. Com més petita, millor.epochs=150: el model veu les dades d'entrenament 150 vegades.
Cada passada completa per totes les dades s'anomena epoch.batch_size=32: en cada pas d'entrenament, el model processa 32 mostres
alhora (no les 960 d'una vegada). Fa l'entrenament més estable i eficient.validation_split=0.15: reserva un 15% de les dades d'entrenament
(144 mostres) per monitoritzar el rendiment a cada epoch sense que el model
les vegi directament. Permet detectar overfitting (quan el model aprèn
les dades d'entrenament de memòria però no generalitza).
Sortida real:
Entrenant... (pot trigar 20–40 segons)
✓ Entrenament completat
Accuracy (test): 99.6%
Loss (test): 0.0392
Corbes d'aprenentatge
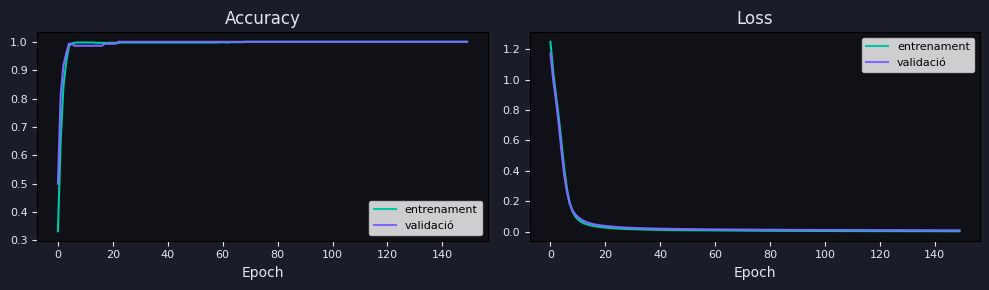
Les corbes mostren l'evolució de l'accuracy i la loss al llarg de les 150 epochs,
tant per a les dades d'entrenament (verd) com per a les de validació (violeta).
S'hi poden observar dos aspectes clau:
Convergència ràpida: tant l'accuracy com la loss arriben a valors excel·lents
en les primeres 20–30 epochs. Les 120 epochs restants serveixen per estabilitzar
els pesos i assegurar que no hi ha variació.
Absència d'overfitting: les corbes d'entrenament i validació es mantenen
juntes durant tot l'entrenament. Si hi hagués overfitting, la corba de validació
s'aturaria d'millorar o empitjoraria mentre la d'entrenament continuava baixant.
En aquest cas, el problema és prou simple i el model prou petit per no caure
en aquesta trampa.
Pas 5 — Validació amb valors reals del simulador
Accuracy alta en el test sintètic no és suficient. Cal provar el model
amb els valors exactes que el simulador IoT-02 generarà en producció.
Aquesta és la validació que hauria d'haver existit en el model v1.
casos = [
("Normal per defecte (LDR=500)", 20.0, 50.0, 500),
("Normal preset (LDR=700)", 22.0, 50.0, 700),
("Calor+Humitat (LDR=600)", 40.0, 90.0, 600),
("Foscor (LDR=50)", 24.0, 45.0, 50),
("Foscor extrem (LDR=30)", 24.0, 45.0, 30),
("Molt lluminós (LDR=4095)", 22.0, 50.0, 4095),
("Molt lluminós (LDR=2558)", 22.0, 50.0, 2558),
("Calor + foscor (LDR=30)", 40.0, 90.0, 30), # cas trampa
]
Sortida real:
Cas Classe Prob Totes les probabilitats
--------------------------------------------------------------------------------
Normal per defecte (LDR=500) NORMAL 100% N:100% C:0% F:0% M:0%
Normal preset (LDR=700) NORMAL 100% N:100% C:0% F:0% M:0%
Calor+Humitat (LDR=600) CALOR 100% N:0% C:100% F:0% M:0%
Foscor (LDR=50) FOSCOR 100% N:0% C:0% F:100% M:0%
Foscor extrem (LDR=30) FOSCOR 100% N:0% C:0% F:100% M:0%
Molt lluminós (LDR=4095) MOLT_LLUM 100% N:0% C:0% F:0% M:100%
Molt lluminós (LDR=2558) MOLT_LLUM 100% N:0% C:0% F:0% M:100%
Calor + foscor (LDR=30) CALOR 100% N:0% C:100% F:0% M:0%
Tots els casos es classifiquen correctament amb 100% de probabilitat.
El cas més interessant és l'últim: Calor + foscor (40°C, 90% RH, LDR=30).
El model classifica CALOR, no FOSCOR. Temperatura alta i humitat alta guanyen
a la llum baixa perquè les zones d'entrenament ho reflecteixen: la classe CALOR
pot tenir LDR fins a 800 (moderada), però la combinació de 40°C i 90% RH
és inequívocament CALOR independentment de la il·luminació.
Pas 6 — Conversió a TFLite i exportació del fitxer .h
Per què cal convertir?
El model Keras que acabem d'entrenar no pot executar-se directament
a l'ESP32 per dos motius:
- Depèn de Python i del runtime de TensorFlow (~500 MB), que no cap
en un microcontrolador. - El format Keras no està optimitzat per a dispositius amb memòria limitada.
TFLite Micro resol tots dos problemes:
converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()
El TFLiteConverter fa dues coses:
- Serialitza el model en format FlatBuffer: un format binari compacte,
sense dependències externes, dissenyat per a dispositius encastats. - Elimina tot el que no és necessari per fer inferències: l'historial
d'entrenament, les funcions de gradient, l'optimitzador, etc.
Sortida real:
Mida aproximada model Keras: ~1 KB (només pesos)
Mida model TFLite: 3008 bytes (2.9 KB)
Factor de compressió: ~0.2x
✓ model_ambient.tflite guardat
Nota sobre el factor de compressió: en aquest cas el model TFLite és
lleugerament més gran que els pesos Keras sols perquè el format FlatBuffer
inclou metadades addicionals (estructura del model, noms de les capes,
informació de quantització, etc.) que TFLite Micro necessita per executar
el model sense cap altre context. Per a models grans (desenes de MB),
el factor de compressió és molt favorable. Per a models tan petits com
el nostre, les metadades dominen.
Generació del fitxer .h
El fitxer .tflite és un binari. Per incrustar-lo al firmware de l'Arduino,
cal convertir-lo en un array de bytes en C:
data = tflite_model
lines = []
for i in range(0, len(data), 12):
chunk = data[i:i+12]
lines.append(' ' + ', '.join(f'0x{b:02x}' for b in chunk))
hex_block = ',\n'.join(lines)
Això és equivalent a l'eina de línia de comandes xxd -i model.tflite > model.h
disponible en sistemes Unix. El resultat és un fitxer C vàlid que declara
l'array del model com una constant global.
Primeres línies del fitxer generat:
// model_ambient.h — generat automàticament per Colab
// Model: classificador_ambient_v2 (Dense 3→12→8→4, float32)
//
// 4 CLASSES:
// 0 · NORMAL → LED verd
// 1 · CALOR → LED vermell + relé (ventilació)
// 2 · FOSCOR → LED groc
// 3 · MOLT_LLUM → LED blanc
//
// Normalització d'entrades:
// temp_norm = temp_C / 50.0
// hum_norm = hum_pct / 100.0
// ldr_norm = ldr_raw / 4095.0
//
// Accuracy (test sintètic): 99.6%
// Mida: 3008 bytes (2.9 KB)
#pragma once
#define TF_NUM_OPS 3 // FullyConnected + ReLU + Softmax
alignas(8) const unsigned char g_model[] = {
0x1c, 0x00, 0x00, 0x00, 0x54, 0x46, 0x4c, 0x33, 0x00, 0x00, 0x0e, 0x00,
// ... 3008 bytes en total
};
const unsigned int g_model_len = 3008;
Dues línies d'aquest fitxer mereixen atenció especial:
#pragma once: directive del preprocessador que assegura que el fitxer
s'inclou una sola vegada durant la compilació, evitant definicions duplicades.alignas(8): força que l'array comenci en una adreça de memòria múltiple
de 8 bytes. TFLite Micro necessita aquesta alineació per llegir correctament
els valors de punt flotant de 32 bits (4 bytes) i de 64 bits (8 bytes)
que formen els pesos del model.
On va el fitxer generat
Un cop descarregat, el fitxer model_ambient.h s'ha de posar
a la mateixa carpeta que el sketch Arduino:
Arduino/IoT-02_TinyML_classificador/
├── IoT-02_TinyML_classificador.ino
├── IoT-02_pinout.h
└── model_ambient.h ← aquí
L'Arduino IDE inclourà automàticament tots els fitxers .h que estiguin
a la mateixa carpeta que el .ino principal.
Resum del pipeline complet
┌─────────────────────────────────────────────────────────────────┐
│ Pas 1 · Imports Eines: TensorFlow, NumPy │
│ Pas 2 · Dades 300 mostres × 4 classes = 1.200 │
│ Pas 3 · Visualització Verificar zones abans d'entrenar │ ← imprescindible
│ Pas 4 · Entrenament 188 paràmetres, 150 epochs, 99.6% │
│ Pas 5 · Validació real Provar amb valors exactes del HW │ ← imprescindible
│ Pas 6 · Exportació 3.008 bytes → model_ambient.h │
└─────────────────────────────────────────────────────────────────┘
Els dos passos marcats com a imprescindibles són els que el model v1 no va fer
correctament. La visualització hauria revelat que la zona NORMAL (LDR 0.30–0.90)
no incloïa el valor per defecte del simulador (LDR = 0.12). La validació real
hauria confirmat el problema abans del desplegament.
La lliçó: en ML, el pipeline no acaba quan l'accuracy és alta.
Acaba quan el model funciona correctament amb les dades del sistema real
on s'ha de desplegar.
Document elaborat per al curs IoT amb IA — Col·legi d'Enginyers de Catalunya